
2017 年最后一天,祝来年顺利
学了点 Python 后,总是想找点东西练下手,在知乎上一番了解之后,打算写一个爬虫。据说爬虫的初学者都要爬一次豆瓣电影 Top250。但我偏不。我选择豆瓣读书 Top250。
爬虫?
爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。——某度百科
自动抓取互联网信息?不明觉历,但了解过后其实并不是什么深奥的东西。大致可以分为三个步骤。
- 获取网页数据
- 分析网页的数据,拿到想要的信息
- 漂亮地输出
你需要了解
获取网页数据
获取网页数据方法很多,特别是一些动态网页。爬豆瓣读书 Top250,是静态的。数据都在网页的源码里。所以只需要拿到 TML 源码就成功了。
拿到 URL
首先,我们要拿到 Url,也就是所谓的网址。https://book.douban.com/top250,第一个页面简单。怎么获取后面的几页呢?
第一个方法,分析源代码,只要获得了第一页的源码,接着就能拿到接下来几页的 Url 啦。
当然还有更简单的,观察网址发现star=后接的数字就是本页第一本书的排行。其实它并不一定是 25 的倍数,任何数字都可以。只是从 250 开始就不会有书了。
用 Python 可以这样'https://book.douban.com/top250'+'?start='+str(pn*25),让 pn 从 0,到 9 迭代,就可以啦。

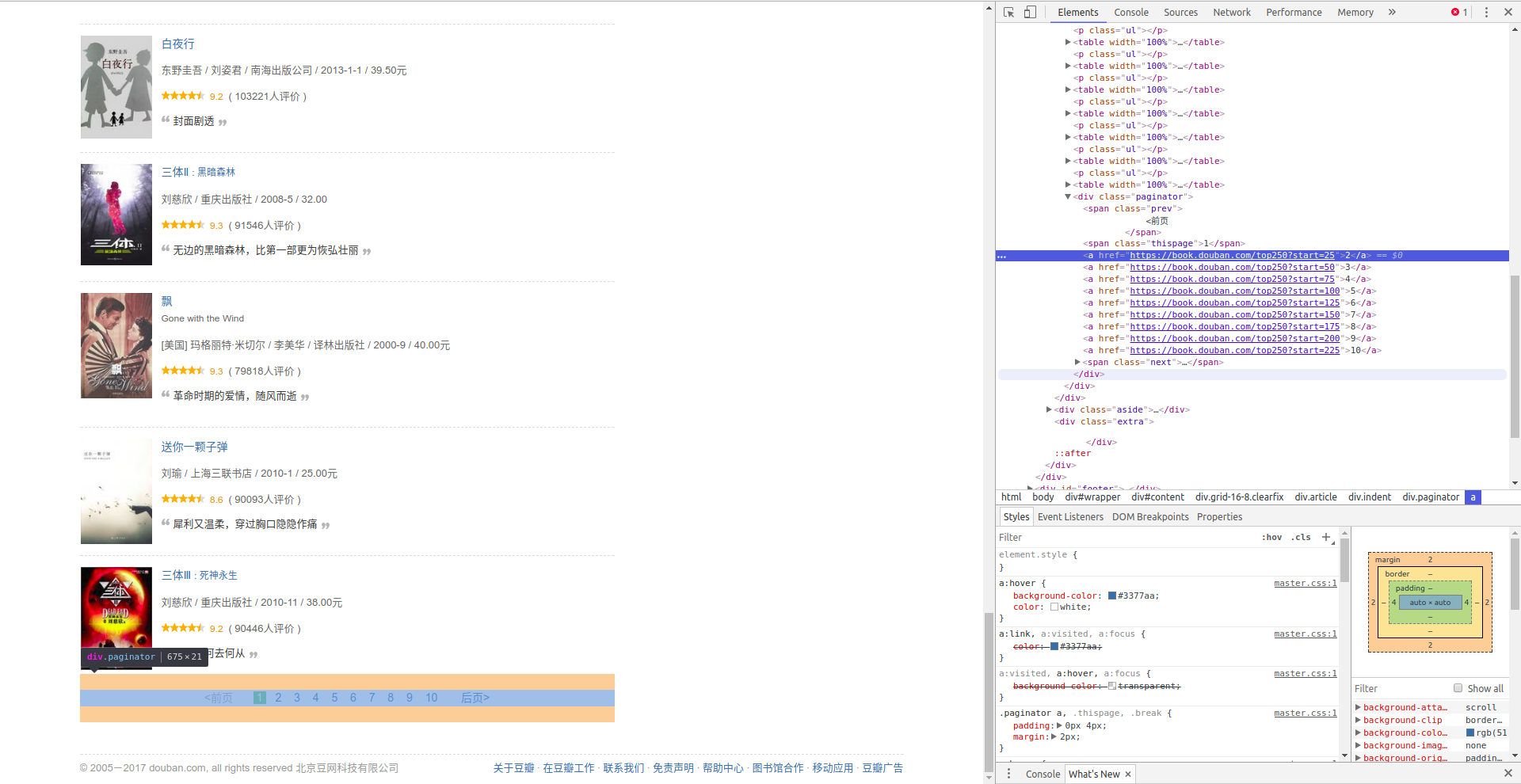
拿到网页源码
有了 Url 要拿到网页源码只要借助 Python 的内建模块urllib就可以啦。
首先构造一个 Request,为了获得的源码尽可能和我看到的保持一致,除了 Url 还要加上 User-Agent。就可以轻松地获取网页源码啦。
from urllib import request
user_agent='Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:57.0) Gecko/20100101 Firefox/57.0'
header={'User-Agent':user_agent}
for pn in range(10):
url='https://book.douban.com/top250'+'?start='+str(pn*25)
get=request.Request(url,headers=header) # 构造一个 Request 对象
with request.urlopen(get) as r: # 发送 GET 请求
content=(r.read().decode('utf-8'))
print(type(content))
# content 就是 string 类的 html 源码分析数据
分析 HTML 用到了 Python 的 lXML 模块。他可以解析 string 类的 html 源码 为 DOM 树,还能通过 xPath 过去读取网页的元素。再加上点正则,就能拿到想要的数据啦。
这次我抓取书名、作者、译者、出版社、出版年月、售价、评分和简评。
看源码发现书本有关的数据都在一个 valign 属性为 top 的 td 标签中。(竟然是表格,怪不得教程都抓豆瓣电影) 先提取出来。

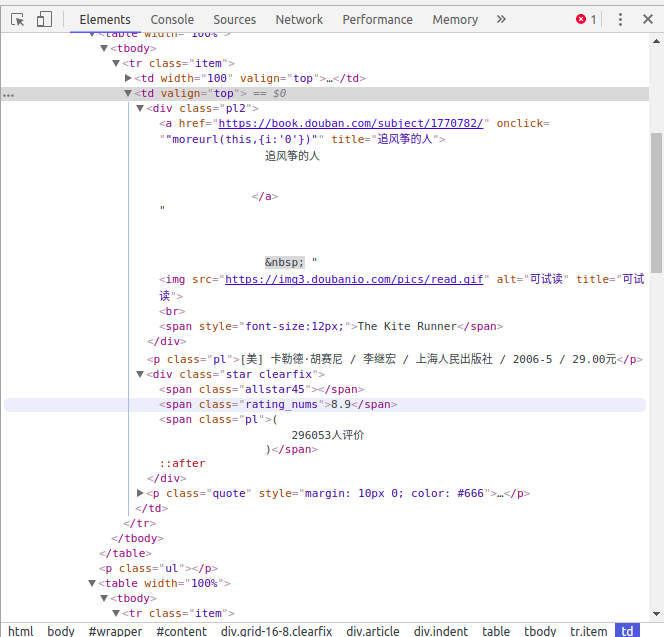
for i in content.xpath('//tr[@class="item"]/td[@valign="top"]'):标题
def rm_empty(ls):
nl=[]
for v in ls:
v=v.strip()
if len(v)>0:
nl.append(v)
return nl
for i in content.xpath('//tr[@class="item"]/td[@valign="top"]'):
#xpath 返回的是一个 list
title=rm_empty(i.xpath('div[@class="pl2"]/a/text()'))
# 同样的标签有两个,其中一个是空的要筛掉
if title !=None:
pass对象
Book
这样就拿到了标题,现在可以构造一个书本的类
class Book(object):
"""docstring for Book."""
def __init__(self, title):
self.title = title
# self.author=author
self.tsl='None'
# self.price=price
# self.pub=pub
# self.date=date
# self.rate=rate
self.comment='None'
def __str__(self):
if self.tsl =='None':
return " 书名: %s\n作者:%s\n出版社:%s\t出版年月:%s\n售价:%s\t评分:%s\n简评:%s"%(self.title, self.author, self.pub, self.date, self.price, self.rate, self.comment)
else:
return " 书名: %s\n作者:%s\t译者:%s\n出版社:%s\t出版年月:%s\n售价:%s\t评分:%s\n简评:%s"%(self.title, self.author, self.tsl, self.pub, self.date, self.price, self.rate, self.comment)Page
同样也可以构造一个 Page 类
class Page(object):
"""docstring for Page."""
def __init__(self,pn):
self.pn=pn
user_agent='Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:57.0) Gecko/20100101 Firefox/57.0'
self.header={'User-Agent':user_agent}
self.url = 'https://book.douban.com/top250'+'?start='+str(pn*25)
def get_request(self):
return(request.Request(self.url,headers=self.header))
Book 其他的属性
同样观察 HTML 源码,通过 xpath 获取,分别作为 book 对应的属性值
info=i.xpath('p[@class="pl"]/text()')
info=re.split(r'\s+/\s+',info[0]) #re 是内建的正则模块,以 “若干个空格 / 若干个空格,分割字符串
comment=i.xpath('p[@class="quote"]/span[@class="inq"]/text()')#拿到评论
rate=i.xpath('div[@class="star clearfix"]/span[@class="rating_nums"]/text()')#拿到评分
#拿到其他属性
for j in range(len(info)-1):
b=Book(title[0])
b.price=info[-1]
b.date=info[-2]
b.pub=info[-3]
b.author=info[0]
b.rate=rate[0]
if len(comment)>0:
b.comment=comment[0]
if len(info)==5:
b.tsl=info[-4]漂亮地输出
对于每个 book 写好 book 类的__str__函数
def __str__(self):
if self.tsl =='None':
return " 书名: %s\n作者:%s\n出版社:%s\t出版年月:%s\n售价:%s\t评分:%s\n简评:%s"%(self.title, self.author, self.pub, self.date, self.price, self.rate, self.comment)
else:
return " 书名: %s\n作者:%s\t译者:%s\n出版社:%s\t出版年月:%s\n售价:%s\t评分:%s\n简评:%s"%(self.title, self.author, self.tsl, self.pub, self.date, self.price, self.rate, self.comment)然后增加点交互,和提示,就大功告成啦。
完整代码
from urllib import request
from lxml import html
import re
# user_agent='Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:57.0) Gecko/20100101 Firefox/57.0'
url_list=[]
# for pn in range(10):
# url='https://book.douban.com/top250'+'?start='+str(pn*25)
# url_list.append(url)
# # print(url_list)
def rm_empty(ls):
nl=[]
for v in ls:
v=v.strip()
if len(v)>0:
nl.append(v)
return nl
class Page(object):
"""docstring for Page."""
def __init__(self,pn):
self.pn=pn
user_agent='Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:57.0) Gecko/20100101 Firefox/57.0'
self.header={'User-Agent':user_agent}
self.url = 'https://book.douban.com/top250'+'?start='+str(pn*25)
def get_request(self):
return(request.Request(self.url,headers=self.header))
class Book(object):
"""docstring for Book."""
def __init__(self, title):
self.title = title
# self.author=author
self.tsl='None'
# self.price=price
# self.pub=pub
# self.date=date
# self.rate=rate
self.comment='None'
def __str__(self):
if self.tsl =='None':
return " 书名: %s\n作者:%s\n出版社:%s\t出版年月:%s\n售价:%s\t评分:%s\n简评:%s"%(self.title, self.author, self.pub, self.date, self.price, self.rate, self.comment)
else:
return " 书名: %s\n作者:%s\t译者:%s\n出版社:%s\t出版年月:%s\n售价:%s\t评分:%s\n简评:%s"%(self.title, self.author, self.tsl, self.pub, self.date, self.price, self.rate, self.comment)
def start(choice,dir=None):
print(' 开始爬取')
Book_list=[]
for pn in range(10): # 多页
print(' 正在爬取第%d页'%(pn+1))
page=Page(pn)
get=Page.get_request(page)
with request.urlopen(get) as r:
content=html.fromstring((r.read().decode('utf-8')))
# print(content)
for i in content.xpath('//tr[@class="item"]/td[@valign="top"]'):
title=rm_empty(i.xpath('div[@class="pl2"]/a/text()'))
if title !=None:
info=i.xpath('p[@class="pl"]/text()')
info=re.split(r'\s+/\s+',info[0])
comment=i.xpath('p[@class="quote"]/span[@class="inq"]/text()')
rate=i.xpath('div[@class="star clearfix"]/span[@class="rating_nums"]/text()')
for j in range(len(info)-1):
b=Book(title[0])
b.price=info[-1]
b.date=info[-2]
b.pub=info[-3]
b.author=info[0]
b.rate=rate[0]
if len(comment)>0:
b.comment=comment[0]
if len(info)==5:
b.tsl=info[-4]
Book_list.append(b)
print(' 爬取完成')
if choice=='1':
dir=input(' 输入保存的目录\n如:/home/usrname/book.txt')
with open(dir,'w') as f:
for book in Book_list:
print(Book_list.index(book)+1,file=f)
print(book,file=f)
print('++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++\n',file=f)
f.close()
elif choice =='2':
for book in Book_list:
print(Book_list.index(book)+1)
print(book)
print('++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++\n')
choice=input('[1]: 保存到文件\n[2]: 直接输出')
start(choice)或许这就是所谓的「面条代码」吧。
运行效果

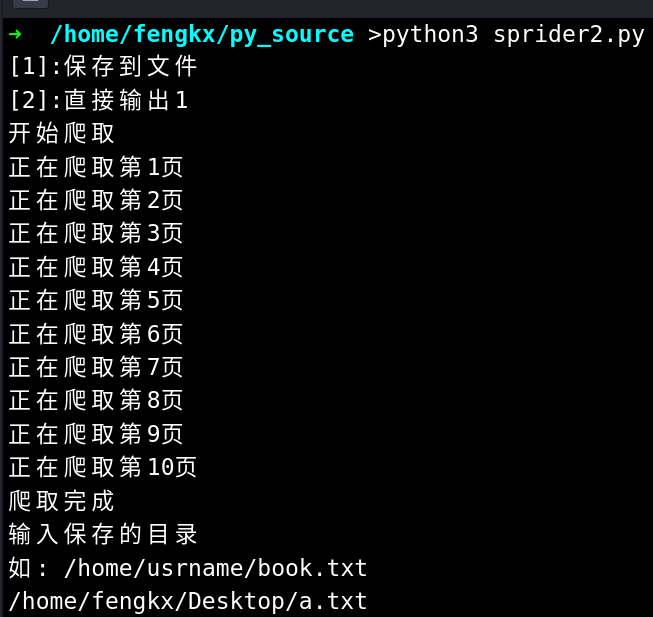

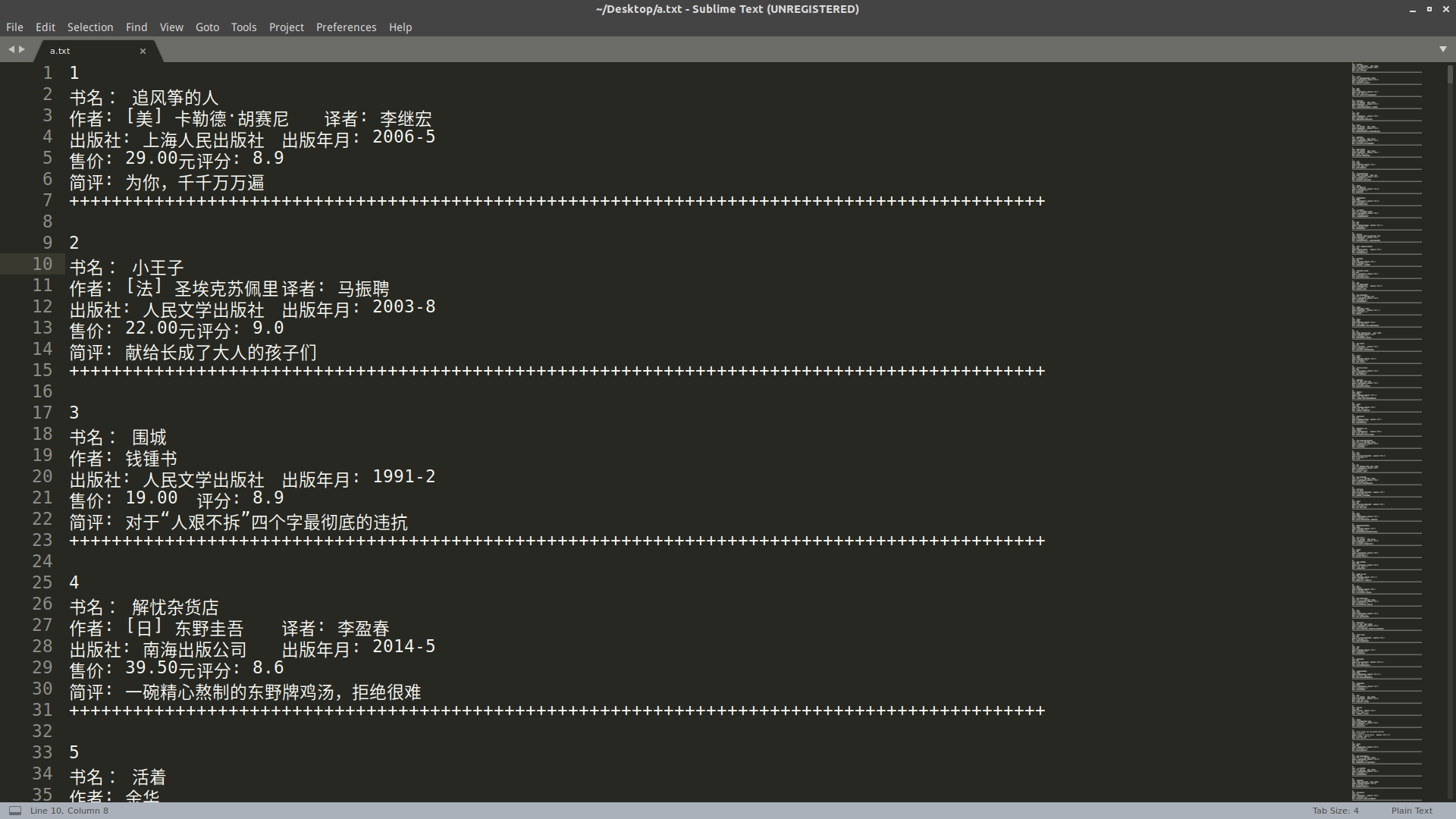
参考文章
本文链接: https://www.fengkx.top/post/first-sprider/
发布于: 2017-12-31