
大佬们都这么说看 CSAPP 不做 Lab 就等于少看了一半。CSAPP 的 Bomb Lab 对我来说,已经算是 “久仰大名” 了。今天 (2019-5-7) 就做了一下。复盘的同时也记录一下,算是检验一下自己的理解程度。
准备工作
Bomb Lab 概览
首先要下载Bomb Lab地址在这里选择self study hanout就好了。还有配套的 README 和视频视频里面带着我们复习了一下汇编,还介绍了可能用用到的工具和 gdb 命令。
解压后能看到一个.c文件和一个可执行文件。打开.c文件可以看到程序的主体逻辑,有 6 个 phase 对应 6 个解密字符串。显然我们就是要逆向这个可执行文件找到这六个字符串。
还有一处很人性化的地方就是这个可执行文件提供了一个命令行参数来从文件准行读取输入。这样我们做出来的字符串可以写在一个文件里面,通过 gdb 的set arg命令设置从文件读取就不用重复劳动啦~
gdb
gdb 的默认功能比较简陋,当然选择peda。peda汇编默认用intel语法。把下面这两行注释掉就能换成CSAPP里面使用的AT&T语法了。
756 ~ │ #self.execute(“set disassembly-flavor intel”)
6158 ~ │ #peda.execute(“set disassembly-flavor intel”)
objdump
objdump -t bomb看符号表
objdump -d bomb > asm返汇编重定向到文件
我们可以通过b explode_bomb和b phase_<第几关>在炸弹爆炸前和对应的函数处下断点。
通关流程
第一关
gdb 进到phase_1这个函数看汇编可以轻松看出只要eax为 0 就能通关。eax就是strings_not_equal的返回值。只要字符串相等就能通关。

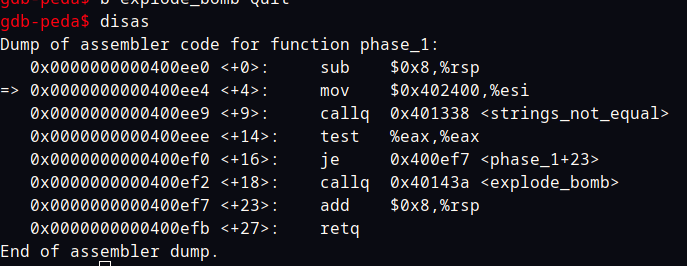
如果进到strings_not_equal函数看汇编代码可以看到,函数就是先比较我们输入的字符串和0x402400地址处的是否相同相同则继续逐位比较。完全相同则返回 0,否则返回 1。


答案就是Border relations with Canada have never been better.
第二关
同样的方法在phase_2下断点看汇编代码

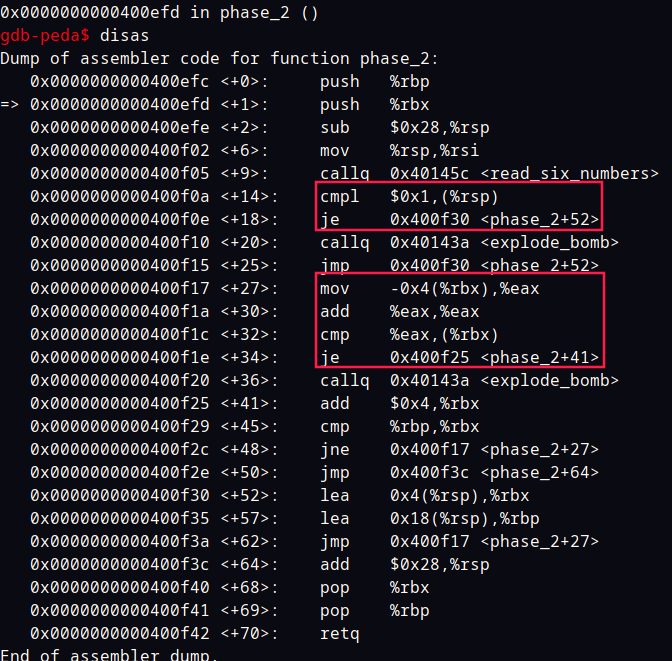
从偏移地址第 14 处可以看出第一个数是 1
偏移地址 26 处看出后面的一个数是前一个数两倍。
答案就是1 2 4 8 16 32
第三关

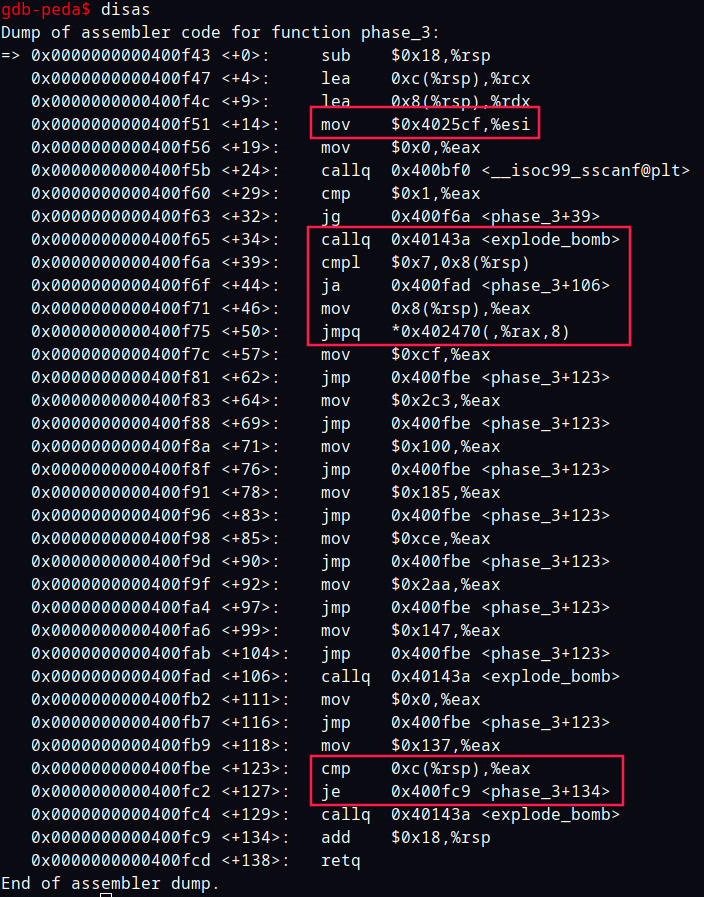
看phase_3的汇编, esi被置为0x4025cf, 然后调用了有sscanf的函数

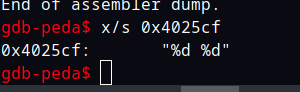
可以想象这个就是对应scanf的格式字符串,输入两个数空格分割
紧接着进行判断,判断确定输入了两个数。
偏移地址 34 处可以看出第一个参数要小于等于 7。然后以第一个参数为倍数,0x402470为基址跳转到跳转到对应位置。
对应位置会用一个立即数给eax赋值。最终都会跳转到偏移地址 123 处,将第二个数与eax也就是对应之前那个立即数比较,相等就通关了。
例如 第一个数为 2 时会跳到偏移地址 64,0x2c3 对应十进制数 707。
答案之一就是2 707
第四关

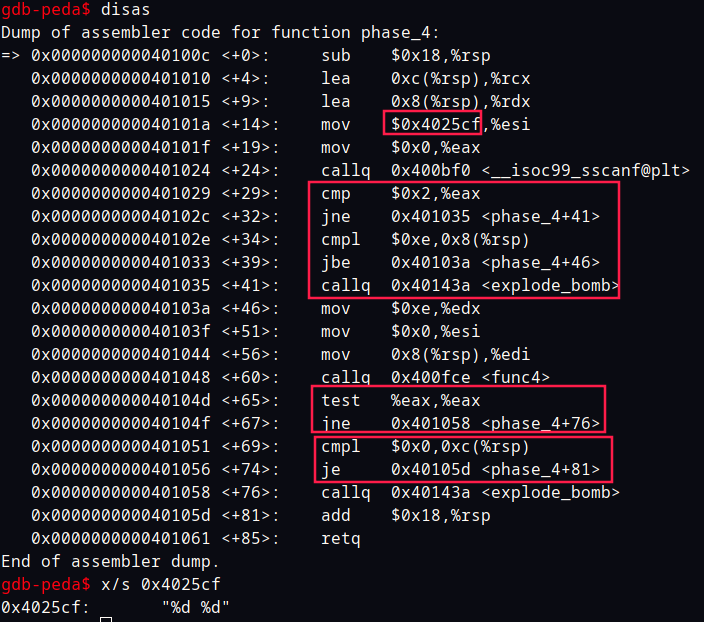
看汇编,同样的套路0x4025cf就是 scanf 的格式字符串,检测输入了两数。
偏移地址 39 处有一个判断,可以看出第一个数要求小于 0xe(14)然后调用了一个func4检查它的返回值eax要为 0。
偏移地址 69 可以看出第二个数的位置经过func4之后要为 0
看func4汇编

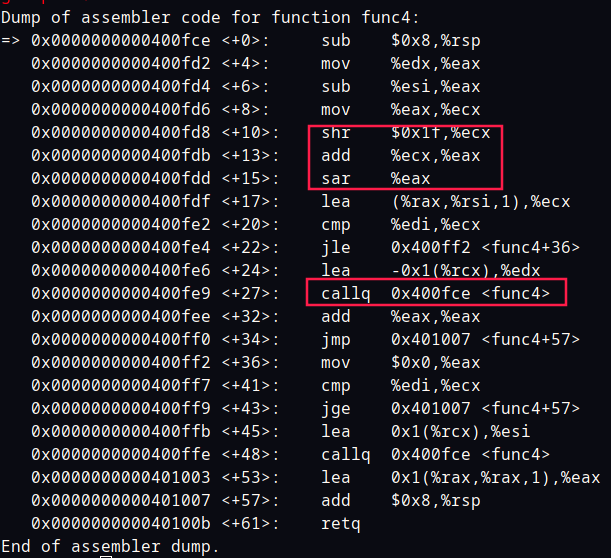
看到有移位操作,有递归调用,分支也挺多的。咋一看看不出来,只能耐心的读懂代码
下面是等价的 c 代码
int func4(int a,int b, int c, int d) {
/*
a in %edi, b in %esi, c in %edx, d in %ecx
r in %eax
*/
//a 输入的第一个数
c=0xe; //phase_4 调用前 func4 前初始化
b=0
r= c-b;
d = r;
d>>31;
r=r+d;
r>>1;
d=r+b;
if(d<=a) {
r=0;
if(d>=a) {
return r;
} else {
b=d+1;
func4(....);
r=2r+1;
return r;
}
} else {
c=d-1;
func4(....);
r=2r;
return r;
}
}
根据已知信息,r 要为 0。而且 func4 没有更改输进去的第二个数。所以第二个数就是要为 0。
看 c 代码可知,使 r 为 0 的条件是d==a。a 就是输入的第一个数。
可以看到d=((c-b) + ((c-b)>>31))>>1 + b。由于 b=0, c=0xe 0xe>0 所以 (c-b)>>31 == 0
化简可知d=c/2, 所以第一个数为 7。
答案7 0
第五关

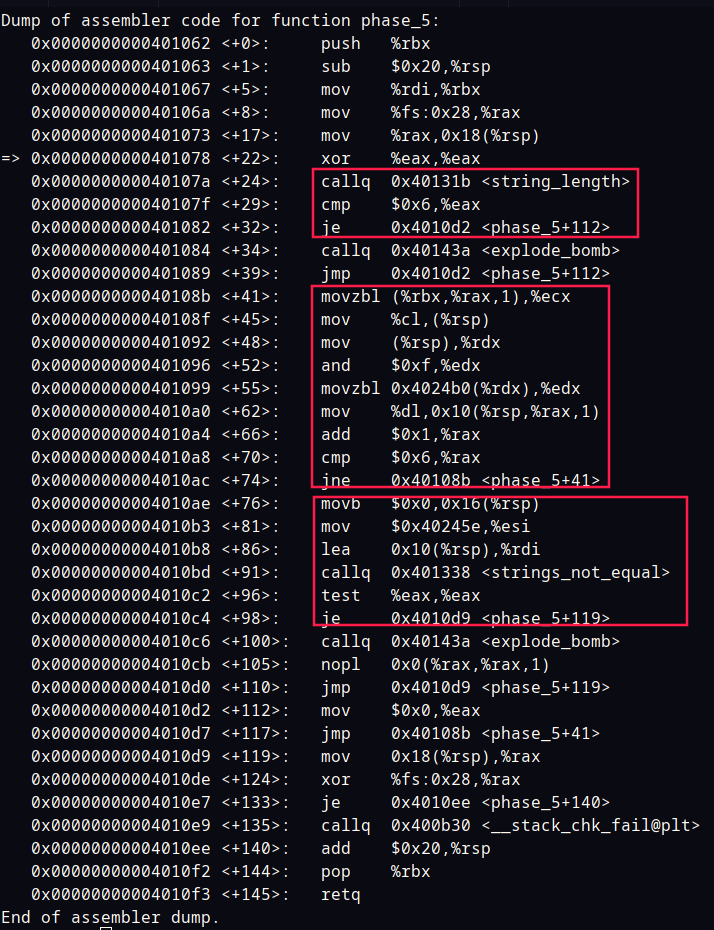
首先判断输入的字符串长度要为 6
然后进入+41 - +74 这个循环。
循环中取输入的字符串每个字符的 ascii 码低四位作为偏移量在 0x4024b0取值存入到栈 (% rsp+10)。
+76 - +98比较生成的字符串和0x40245e的字符串如果相等就通关了。


我们知道数字 0-9 的 ascii 码低四位与数字本身是对应的,范围是0x30 ~ 0x39, 用 Python 的chr函数构造处要输入的字符串
答案9?>567
第六关
第六关 gdb 调试发现循环很多一个套一个。然后就选择直接死啃汇编。
Dump of assembler code for function phase_6:
=> 0x00000000004010f4 <+0>: push %r14
0x00000000004010f6 <+2>: push %r13
0x00000000004010f8 <+4>: push %r12
0x00000000004010fa <+6>: push %rbp
0x00000000004010fb <+7>: push %rbx
0x00000000004010fc <+8>: sub $0x50,%rsp
0x0000000000401100 <+12>: mov %rsp,%r13
0x0000000000401103 <+15>: mov %rsp,%rsi
0x0000000000401106 <+18>: callq 0x40145c <read_six_numbers>
0x000000000040110b <+23>: mov %rsp,%r14
0x000000000040110e <+26>: mov $0x0,%r12d
0x0000000000401114 <+32>: mov %r13,%rbp
0x0000000000401117 <+35>: mov 0x0(%r13),%eax
0x000000000040111b <+39>: sub $0x1,%eax
0x000000000040111e <+42>: cmp $0x5,%eax
0x0000000000401121 <+45>: jbe 0x401128 <phase_6+52>
0x0000000000401123 <+47>: callq 0x40143a <explode_bomb>
0x0000000000401128 <+52>: add $0x1,%r12d
0x000000000040112c <+56>: cmp $0x6,%r12d
0x0000000000401130 <+60>: je 0x401153 <phase_6+95>
0x0000000000401132 <+62>: mov %r12d,%ebx
0x0000000000401135 <+65>: movslq %ebx,%rax
0x0000000000401138 <+68>: mov (%rsp,%rax,4),%eax
0x000000000040113b <+71>: cmp %eax,0x0(%rbp)
0x000000000040113e <+74>: jne 0x401145 <phase_6+81>
0x0000000000401140 <+76>: callq 0x40143a <explode_bomb>
0x0000000000401145 <+81>: add $0x1,%ebx
0x0000000000401148 <+84>: cmp $0x5,%ebx
0x000000000040114b <+87>: jle 0x401135 <phase_6+65>
0x000000000040114d <+89>: add $0x4,%r13
0x0000000000401151 <+93>: jmp 0x401114 <phase_6+32>
0x0000000000401153 <+95>: lea 0x18(%rsp),%rsi
0x0000000000401158 <+100>: mov %r14,%rax
0x000000000040115b <+103>: mov $0x7,%ecx
0x0000000000401160 <+108>: mov %ecx,%edx
0x0000000000401162 <+110>: sub (%rax),%edx
0x0000000000401164 <+112>: mov %edx,(%rax)
0x0000000000401166 <+114>: add $0x4,%rax
0x000000000040116a <+118>: cmp %rsi,%rax
0x000000000040116d <+121>: jne 0x401160 <phase_6+108>
0x000000000040116f <+123>: mov $0x0,%esi
0x0000000000401174 <+128>: jmp 0x401197 <phase_6+163>
0x0000000000401176 <+130>: mov 0x8(%rdx),%rdx
0x000000000040117a <+134>: add $0x1,%eax
0x000000000040117d <+137>: cmp %ecx,%eax
0x000000000040117f <+139>: jne 0x401176 <phase_6+130>
0x0000000000401181 <+141>: jmp 0x401188 <phase_6+148>
0x0000000000401183 <+143>: mov $0x6032d0,%edx
0x0000000000401188 <+148>: mov %rdx,0x20(%rsp,%rsi,2)
0x000000000040118d <+153>: add $0x4,%rsi
0x0000000000401191 <+157>: cmp $0x18,%rsi
0x0000000000401195 <+161>: je 0x4011ab <phase_6+183>
0x0000000000401197 <+163>: mov (%rsp,%rsi,1),%ecx
0x000000000040119a <+166>: cmp $0x1,%ecx
0x000000000040119d <+169>: jle 0x401183 <phase_6+143>
0x000000000040119f <+171>: mov $0x1,%eax
0x00000000004011a4 <+176>: mov $0x6032d0,%edx
0x00000000004011a9 <+181>: jmp 0x401176 <phase_6+130>
0x00000000004011ab <+183>: mov 0x20(%rsp),%rbx
0x00000000004011b0 <+188>: lea 0x28(%rsp),%rax
0x00000000004011b5 <+193>: lea 0x50(%rsp),%rsi
0x00000000004011ba <+198>: mov %rbx,%rcx
0x00000000004011bd <+201>: mov (%rax),%rdx
0x00000000004011c0 <+204>: mov %rdx,0x8(%rcx)
0x00000000004011c4 <+208>: add $0x8,%rax
0x00000000004011c8 <+212>: cmp %rsi,%rax
0x00000000004011cb <+215>: je 0x4011d2 <phase_6+222>
0x00000000004011cd <+217>: mov %rdx,%rcx
0x00000000004011d0 <+220>: jmp 0x4011bd <phase_6+201>
0x00000000004011d2 <+222>: movq $0x0,0x8(%rdx)
0x00000000004011da <+230>: mov $0x5,%ebp
0x00000000004011df <+235>: mov 0x8(%rbx),%rax
0x00000000004011e3 <+239>: mov (%rax),%eax
0x00000000004011e5 <+241>: cmp %eax,(%rbx)
0x00000000004011e7 <+243>: jge 0x4011ee <phase_6+250>
0x00000000004011e9 <+245>: callq 0x40143a <explode_bomb>
0x00000000004011ee <+250>: mov 0x8(%rbx),%rbx
0x00000000004011f2 <+254>: sub $0x1,%ebp
0x00000000004011f5 <+257>: jne 0x4011df <phase_6+235>
0x00000000004011f7 <+259>: add $0x50,%rsp
0x00000000004011fb <+263>: pop %rbx
0x00000000004011fc <+264>: pop %rbp
0x00000000004011fd <+265>: pop %r12
0x00000000004011ff <+267>: pop %r13
0x0000000000401201 <+269>: pop %r14
0x0000000000401203 <+271>: retq
End of assembler dump.+32 - +93 和 +65 - +87 是一个两层的嵌套循环。就是判断每个数要不同而且小于等于 6 且 不等于 0,否则炸弹都会爆炸
+108 - +121 循环把输入的每个数都用 7 减去这个数。也就是 a[i] = 7 - a[i]
后面的汇编看了好久也看不出个所以然。于是~无耻的~打开了 ida 按下了 F5


ida 看 phase_6 印证了前两个循环
可以看到 node 这个东西,点进去看到数据段

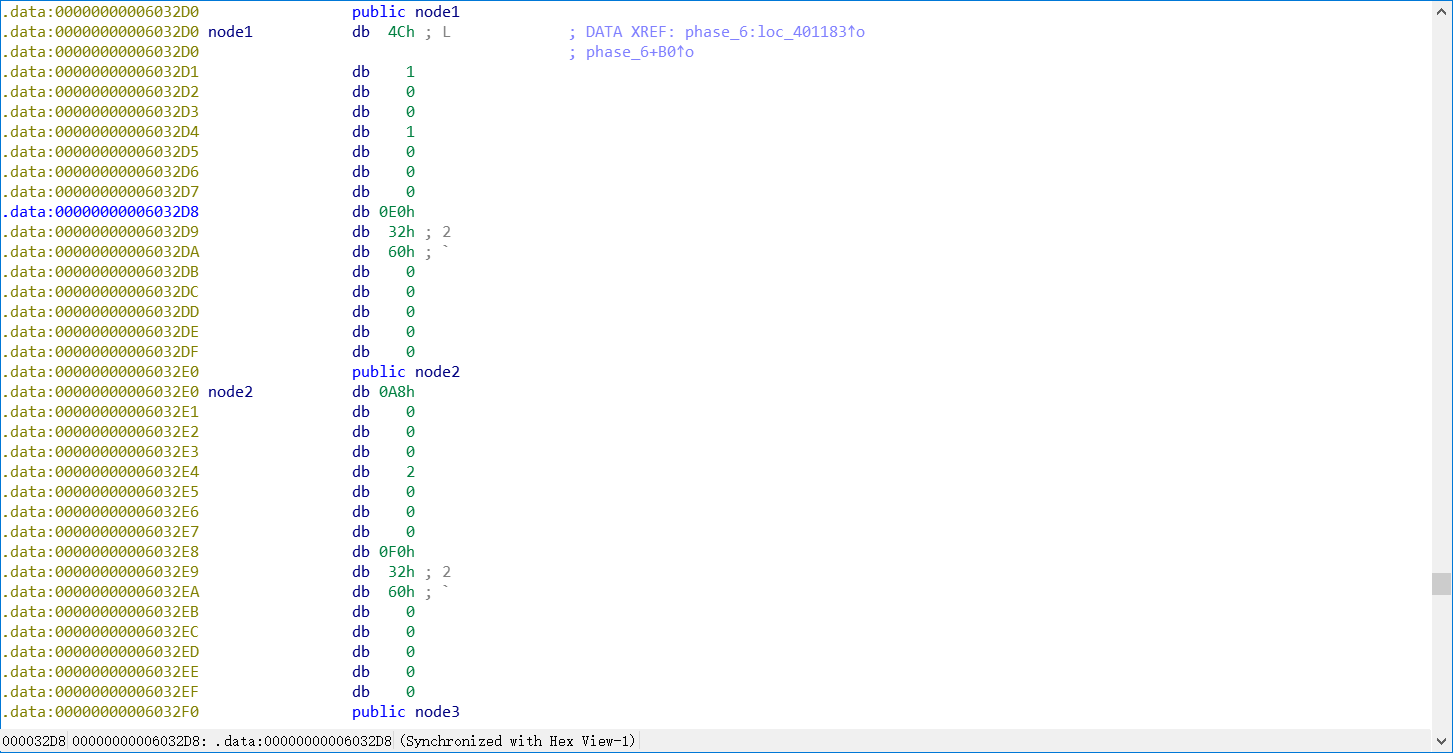
node 一共有 6 个 每个 16 byte

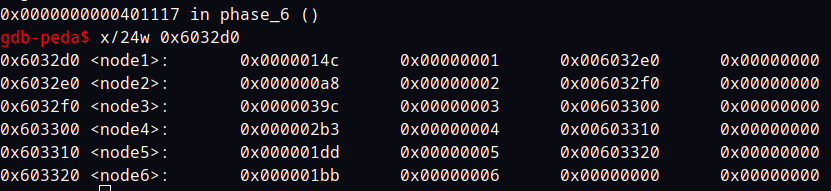
gdb 查看字节,可以更直观的看到这是个链表 每个 node 第三个四字指向下一个 node。

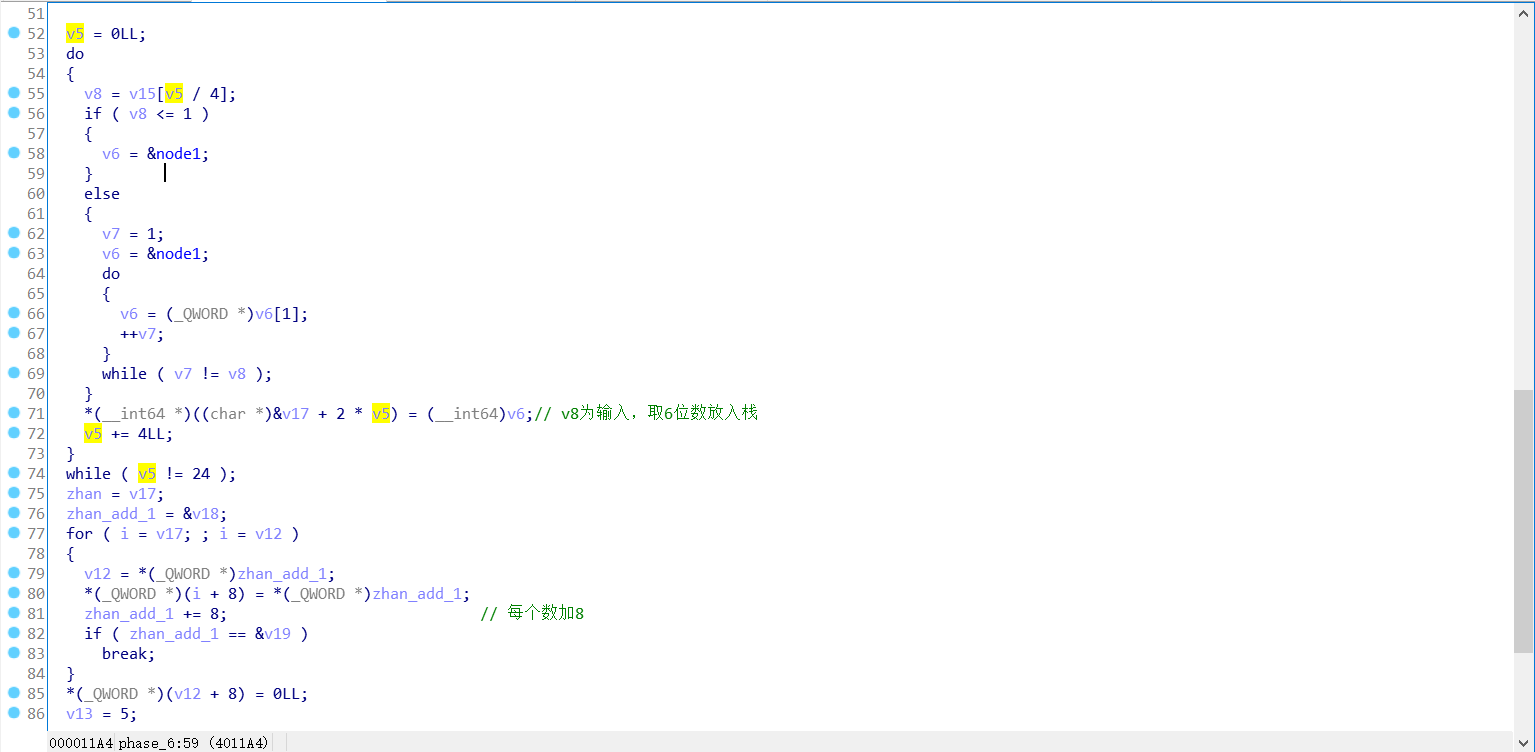


伪代码 53 行的 do-while 的意思是按照输入的数字取第 n 个 node 的数值 (int64) 放入栈中
然后每个数都加 8,要求前一个数大于后一个数则通关。
我们可以从 gdb 看到数值,手工排下序得到3 4 5 6 1 2
但是我们输入的数字之前都被用 7 减过,所以答案是 4 3 2 1 6 5
IDA 大法好!
总结
bomb lab真好玩。
看汇编的时候要整体来看,有时候抓住关键的跳转语句,找到循环会好很多。
好像还有隐藏关卡,先留个坑
本文链接: https://www.fengkx.top/post/csapp-bomb-lab/
发布于: 2019-05-08