
缓存替换算法
缓存替换算法决定了在有限的容量的缓存中,有新的项进入的时候选择哪一项被剔除的问题。
缓存算法有很多
假如我们以K-V形式的缓存为例。通常 KV 形式的缓存为了有O(1)的读取速度都会维护一个HashMap
那么不同的算法的其中一个不同之处就是保存替换时决策所需要的信息而产生的额外的数据结构了。
LRU
LRU (Least recently used) 最近最少使用,实际上就是缓存中最久未被使用的项会被优先剔除。
它的思想是如果一个项很久都没被使用了,那么它应该被剔除缓存。
但是当缓存的访问是循环的顺序遍历,而且缓存容量不足以容纳遍历的项时,缓存项就会频繁进出影响效率。
实现
为了知道最近最少访问的信息通常 LRU 的实现会采用双链表保存缓存项。因为缓存的数量会动态变化,所以会选择链表。而且会有不少的删除节点操作,为了达到O(1)的删除操作所以会用双链表。
type CacheNode struct {
key int
value int
prev *CacheNode
next *CacheNode
}
type LRUCache struct {
size int
capacity int
head *CacheNode
tail *CacheNode
cache map[int]*CacheNode
}我们保存链表的尾指针,每当有缓存项的访问或者新项都将对应的节点移到链表的头。头插入和删除节点的操作都是O(1)
hashlru
还有一种近似的 LRU 算法HashLRU通过两个HashMap的交换实现O(1)的复杂度,在实际的Benchmark中的表现也很好。
LFU
LFU (Least Frequently Used) 最近最不频繁使用,缓存中被使用的次数最少的项会被优先剔除。它认为被用的越少的项越应该移除。
LFU 克服了 LRU 在大规模遍历时的缺点。但是容易导致旧数据的积累。同时新数据因为使用次数少容易反复被移出缓存导致长期无法积累跟大的使用次数。
实现
Leetcode 上有 LFU Cache 的题目
为了维护相关的访问频次信息需要额外的数据结构。一种各操作 (增删查) 都为O(1)的形式是使用两个双链表。其中一个保存访问频次,另一个用于保存某频次对应的节点。因为频次链表会经常有增删操作所以使用双链表。而保存某频次对应节点的链表也可以使用 HashMap 或者动态表。
type CacheNode struct {
key int
value int
prev *CacheNode
next *CacheNode
parent *FreqNode
}
type FreqNode struct {
freq int
head *CacheNode
tail *CacheNode
prev *FreqNode
next *FreqNode
}
type LFUCache struct {
size int
capacity int
cache map[int]*CacheNode
lfuHead *FreqNode
}

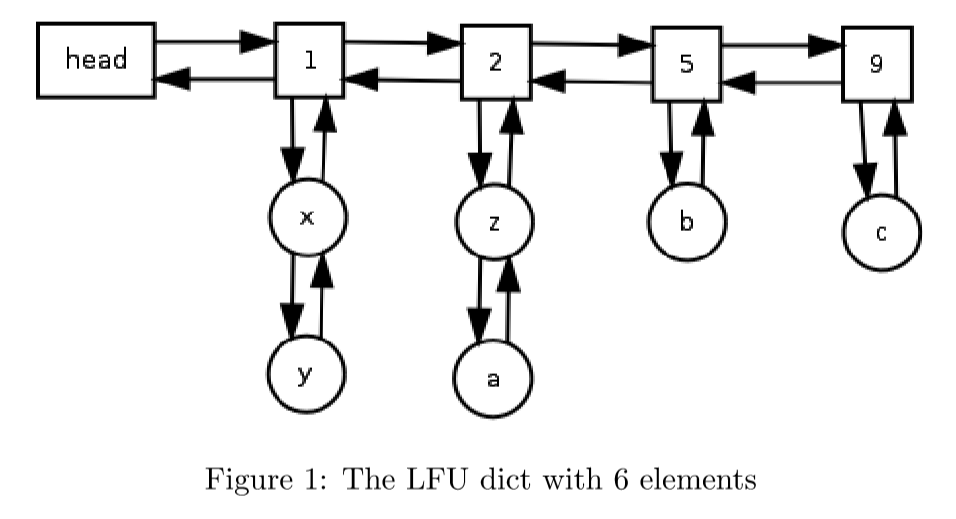
缓存保存一个使用次数为 0 的频次节点的指针。新项加入时,头插入到次数为 1 的频次节点,时间复杂度为O(1)。
当某一个频次的节点 (除 0 以外) 所持有的缓存项个数为 0 时,该频次节点就会被移除。这样保证了 0 频次节点的下一个节点总是缓存中使用次数最少的。
此时,只要在频次节点中维护缓存项链表的尾指针,就知道了缓存中使用此是最少最老旧的缓存项。此番操作 (lfuHead.next.head) 的时间复杂度也是O(1)
ARC
ARC (Adaptive replacement cache) 同时使用 LRU 和 LFU。通过动态调整 LRU,LFU 的容量达到自适应的效果。
缓存中除了 LRU 和 LFU 所需的数据结构外,额外增加了两条链表 LRU 和 LFU 各一个称为 Ghost List。
开始时缓存容量被平分 LRU 和 LFU 两部分。当新项加入时,先加入到 LRU 中。当缓存项被访问而 LFU 中没有时,加入到 LFU 中。
如果缓存项被移除则将它的 Key 加入到对应的 Ghost List 中。每当缓存不命中时,都会检查 Ghost List。假如 Ghost List 中含有当前不命中的 Key 则该 Ghost List 对应的缓存的容量应该增加。
参考文章
- Cache Replacement Policy Wiki
- LFU Cache Wiki
- An O(1) algorithm for implementing the LFU cache eviction scheme
- Hash LRU
- Leetcode discuss
本文链接: https://www.fengkx.top/post/lru-lfu-cache/
发布于: 2020-02-22