
现状 / 起因
NodeRSSBot的公开 Demo @NodeRSS_bot 随着项目的开源一同上线。也运行了有将近两年了。截至今日(2020/11/18)Demo 有活跃订阅源 3900 + 个。Demo 用 docker 部署在了一台 1C1G 的digitalocean主机上,设定为每十五分钟抓取一次。由于每 15 分钟需要抓取 3k + 的源地址是一个不太轻松的活,抓取的部分是单独使用一个 child_process 进行的。随着订阅数的增长,代码中的一些问题也显现了出来。近期发现抓取进程占用的内存相当的高。特别是在网络不畅通的环境(比如墙内),因为got的重试和超时机制,内存占用甚至会突破 Node.js 的限制而导致进程退出。
排查
工具
排查内存占用,首先需要找出哪些东西占用了内存。这就用到了 Chrome Dev Tool 中的 memory 面板,在这里可以加载 v8 的 heapsnapshot 并且提供总览,比较等的视图来查找内存占用(被持有)的原因。具体的用法可以看Google 的官方文档在这里不在赘述。但是官方文档中有部分的东西并没有说的很清楚。比如比较视图的表头几个带#号的含义就困扰了我一阵子。在 tg 群友的推荐下收获这篇文章是个很好的补充。
Node.js 12 中加入了–heapsnapshot-signal选项,可以用来生成 heapshot。
String 占用
找出内存占用最快的方式莫过于将一大一小两个 snapshot 放到对比视图中看差值。kill 一番之后收获.heapsnapshot两个。

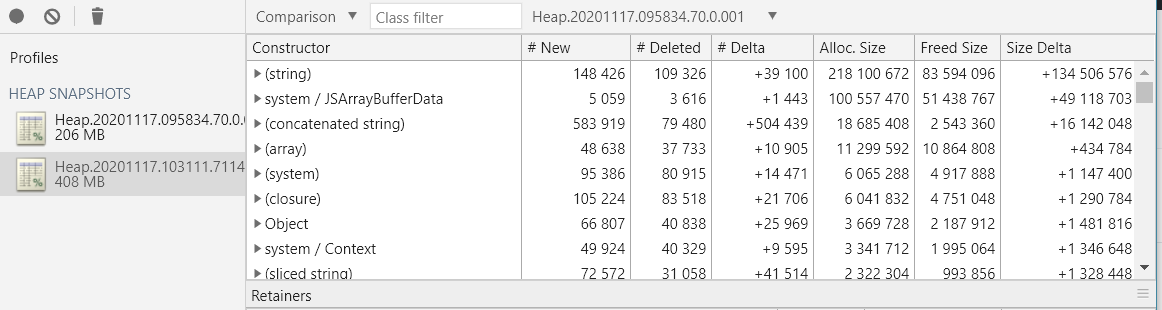
可以看出字符串占了很多,比起别的多了一个数量级。具体来说是 feed 的 xml。下面第二大的 ArrayBufferData 也是同样的东西占的最多。具体到代码的话就是res中的body和rawBody。
找到问题了,挑选一个幸运儿,根据幸运儿的 Retainers 调整代码。直到 res 这两个属性的引用全部被 delete。本地运行fetch.js分析 snapshot。

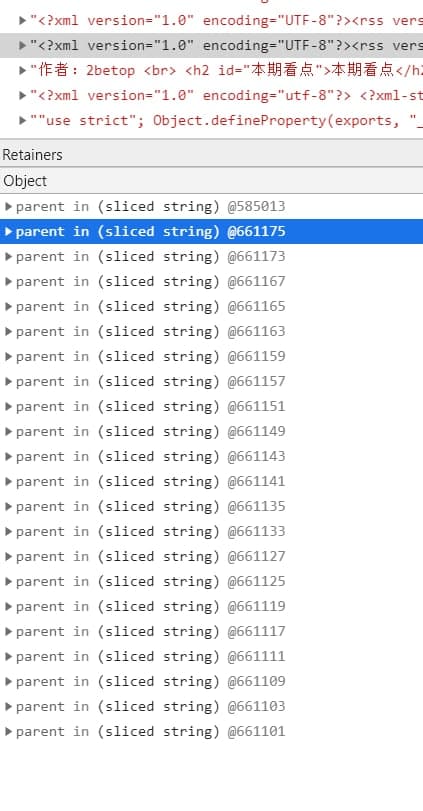
但是发现一个问题,rss-parser 使用的 xml2js 解析整一个 xml string。rss 中的很多 fieldcontent,title等都是这个 string 的 slice。即便除了 sliced string 没有任何别的 retainer,这个 string 也没有被 gc。由于 string 是 read only 的,所以这样的优化有助于计算性能。但是在 RSSBot 中就非常致命了。一个 feed 小的也有几百 KB,snapshot 中看到最大的能有 7M。
解决
考虑到我完全不需要 rss 中除title, link之外的其他 field。所以我决定直接把 rss-parser 拿掉,换用camaro正如 camaro 作者在 README 中写的一样
The whole reason of me creating this is because most of the time, I’m just interested in some of the data in the whole XML mess.

考虑到两次 snapshot 的时间间隔不一致,这样的效果也算是个不小的提升了。但是运行时间长了的话 heap 还是会上到 400MB。还有改进的空间。
p-map => fastq

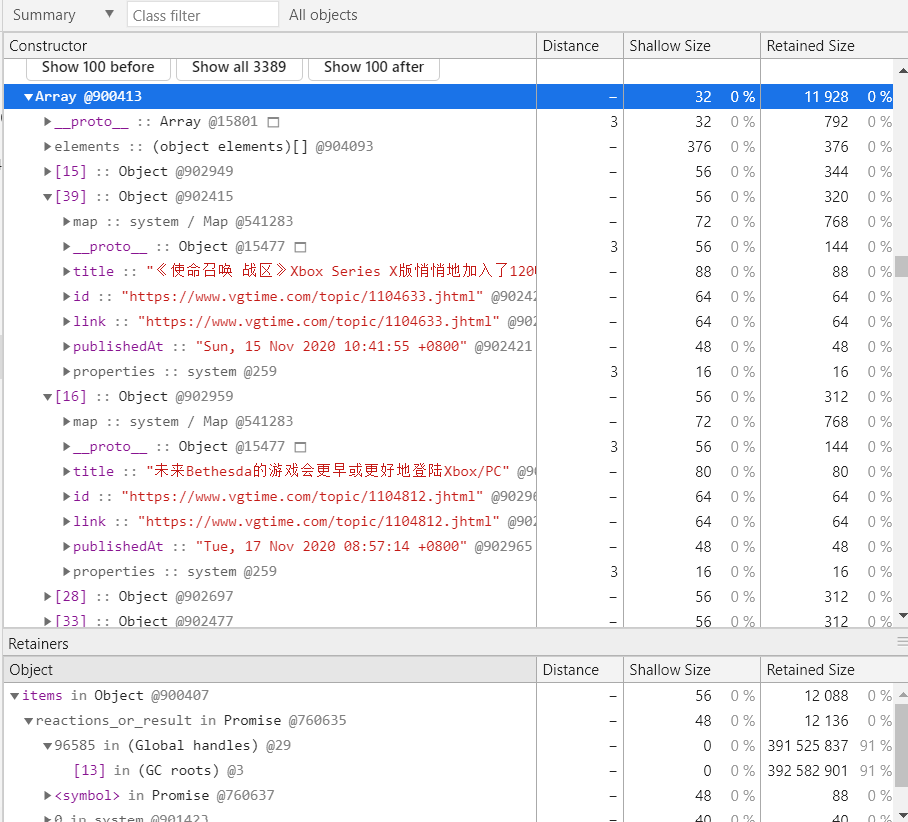
代码中使用 p-map 控制请求的并发数量。本来以为不会出现如此长的数组。但阅读 p-map 源码之后发现,p-map 并不等于任务队列,整个数组和结果数组都会保存起来。(废话)不然怎么叫 map
解决
是误用了,换掉。我没有选择换成同一系列的p-queue, 因为他的 api 设计不太合适。然后找到了fastq, 作者,stars,used by 看下来,再看一下代码。靠谱!果断换掉。

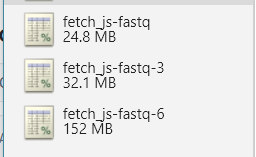
一切看起来是这么的美好~
进一步优化
Manual gc
继续找占用内存的根源,发现还是有一些 xml string 阴魂不散。仔细检查 snapshot,确实应该要被 gc 才对的。于是决定手动 tigger gc。Node.js 提供 --exposed-gc选项。在 child_process 的 execArgv 中加上就能使用global.gc手动触发 gc。递归调用setTimeout做一个定时 3 分钟一次的 gc。效果显著,snapshot 再也没有阴魂不散的 xml string 了。
在本地长期运行,关闭代理模拟大量 feed 出错的情况,多次触发 snapshot,gc 后的 heap 大小表现还是很不错的。

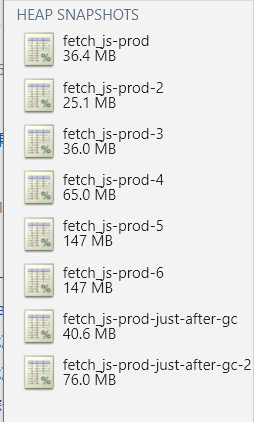
检查 workQueue 情况
用上了fastq之后情况变成了定时向 queue 中 push 要抓取的 feed。这是检查 queue 长度(任务完成 / 堆积情况)就显得很重要了。受到--heapsnapshot-signal启发。绑定信号 handler,在接收到信号时 log 队列长度。Demo 实测concurrency设置在 500 的情况下,默认 40 秒请求 timeout。一轮 queue 清空约用时 3 分钟。
总结感受
heapsnapshot 是分析内存占用的利器。但是网上的资料还是比较少,google 的官方文档也也没有讲清楚一些细节。这么走下来好像很轻松,但是不太熟悉这样的分析,实际上花了很长时间才定位出问题。必须要感谢 tg 群友的提点。
最后上一幅digitalocean的资源占用图。

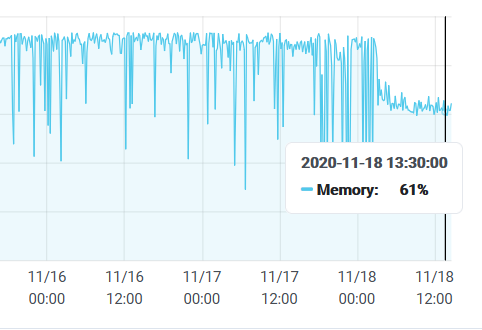
看到这一个阶梯,总算觉得时间没有白费。
未来展望
可能会考虑别的 schedule 的方法而不是统一在一个时间内抓取全部 feed。bot 开始的时候设计就是多个用户订阅同一个 feed 不会多次请求。这当然限制了功能,比如说每个抓取间隔是全局的而不是每个 feed 可调节的。Miniflux则是将(feed_id,user_id)作为一个超键。提供了更丰富的功能,但是也导致会对多用户订阅同一个 feed 时会发多个请求。
本文链接: https://www.fengkx.top/post/node-memory-optimize/
发布于: 2020-11-18